Optimizing Event-Driven Workloads: Our Journey from Lambda Triggers to Polling
Introduction:
A couple of years ago, we completed a major milestone for our product.
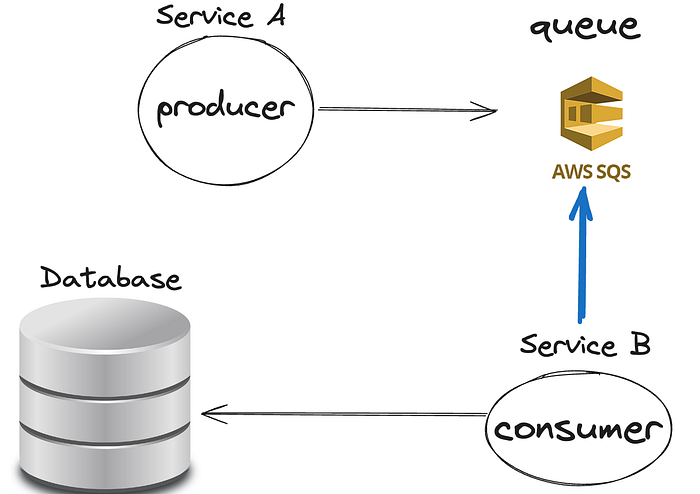
One of the core components, let’s call it Service A, was responsible for performing an analysis, generate data and upload the data to S3.
A reference to this data was sent to an SQS queue, which triggered another component, Service B, that processed the events and wrote them to a database.
The reason we placed a queue between Services A and B was that by decoupling them, we could have control over the load we apply on the database. Processing the requests synchronously would have crashed our database almost instantly.
Aside from data processing, Service B also exposed a customer-facing API consumed by a frontend application.

The Problem:
As we prepared for the milestone, we noticed significant CPU spikes during event processing. These spikes were caused by multiple transactions waiting for row-level locks to be released. With numerous concurrent Lambda functions trying to commit their transactions, the waiting times were causing database client connections to remain active for extended periods, leading to frequent timeouts.

Avoiding Drastic Changes:
In recent years, I have focused on simplifying architectures to avoid over-engineering. Instead of rushing to complex solutions, such as extracting this part to a different compoenent, I decided to experiment with a polling mechanism to replace the SQS-triggered Lambdas.
Polling allowed us to control the database load by limiting the number of items retrieved from the queue at a time.
Additional aspects we had to handle are the Lambda error rate and timeouts.
Timing out on a regular basis caused lots of errors, we wanted to make sure we’re not polluting the logs and metrics with “intended” and “by design” time outs.
Working around the problem:
We began by polling the queue for 10 messages every minute, but quickly ran into the same transaction contention issues. Increasing the interval to 5 minutes reduced the load but slowed down the overall processing time.
To solve this, we needed a long-running mechanism. While running a live Fargate container or an EC2 instance seemed intuitive, we wanted to avoid further distribution of the system.
That’s true, AWS Lambda is not meant or built for long running processes (and also not for predictable workloads, and several more workload types) and is the most expensive compute platform per 1 minute of execution, compared to ECS/EKS/EC2.
However:
1. Processing the entire queue ranged from 45–60 minutes. Obviously the cost overhead marginal (around $1).
2. Adding another component adds more complexity, and is not free of charge. Additional costs could range from infrastructure, maintenance, monitoring, security auditing, etc.
What stood out the most, was avoiding to commit to any solution or architecture. One can always re-think their solution as they scale their customer and/or use case grows.
We applied a simple mechanism for the Lambda with a 15 minute timeout:
1. Check how much time left before execution timeout:
If we have 60 seconds or more - continue polling
otherwise — exit.
2. Poll for messages (MAX of 10)
3. Process the messages
4. Repeat
By continuously polling the queue within a single Lambda invocation, we achieved a balance between load management and processing efficiency.
As mentioned, this lambda also exposes an API, so keeping the logs, error rates and metrics clean served us as well.
We had a single lambda handling the items efficiently, lock and timeout free. This approach allowed us to “clean” the queue within 3–4 executions, with minimal impact on our database.
Code Implementation:
Here’s the code we used to implement the solution:
package main
import (
"context"
"encoding/json"
"fmt"
"github.com/aws/aws-lambda-go/events"
"github.com/aws/aws-lambda-go/lambda"
"github.com/aws/aws-sdk-go/aws"
"github.com/aws/aws-sdk-go/aws/session"
"github.com/aws/aws-sdk-go/service/sqs"
"time"
)
var (
queueURL = "my-queue"
sqsQueue = sqs.New(session.Must(session.NewSession()))
)
func HandleRequest(ctx context.Context, _ events.CloudWatchEvent) error {
deadline, ok := ctx.Deadline()
if !ok {
return fmt.Errorf("unable to retrieve deadline, should not happen")
}
oneMinute := 1 * time.Minute
for {
remainingTime := time.Until(deadline)
if remainingTime <= oneMinute {
return nil
}
result, err := sqsQueue.ReceiveMessage(&sqs.ReceiveMessageInput{
QueueUrl: aws.String(queueURL),
MaxNumberOfMessages: aws.Int64(10),
VisibilityTimeout: aws.Int64(905),
})
if err != nil {
return fmt.Errorf("error receiving messages: %v", err)
}
for _, message := range result.Messages {
var body map[string]any
if err := json.Unmarshal([]byte(*message.Body), &body); err != nil {
// handle error
}
// TODO process the message
if _, err = sqsQueue.DeleteMessage(&sqs.DeleteMessageInput{
QueueUrl: aws.String(queueURL),
ReceiptHandle: message.ReceiptHandle,
}); err != nil {
// handle error
}
}
}
}
func main() {
lambda.Start(HandleRequest)
}Conclusion
There are dozens of platforms, architectures and methods. choose what’s you’re most comfortable with, what works best for you, and most importantly, what serves your customers best.
Your customers don’t care about what’s running behind the scenes, as long as the user experience is fine and you have a reasonable technical solution under the hood that is flexible enough to change.
